Before we get started, this is a very high level view of data structures, I am not a full time software developer just a person passionate about information systems hoping to impart some thoughts.
Let’s design a data model for a CRM (Customer Relationship Management) software.
- First we need people, so we add a table for people.
- Second we need the companies those people work at, so we create a table for companies, there should be a way to link people to companies as contacts or something like that.
- Third we need to log our calls to those people so we have a record of when we called them and notes about the call.
We will mock this up into a diagram first, that way we can get a feel for the data before we go and build it.
Tables
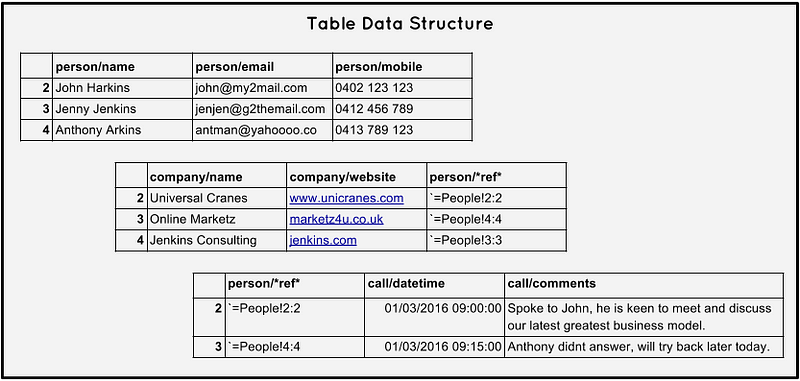
Approaching this traditionally we went up with a design like above, I studied this at uni and and when I think about this I default to a relational table structure. It is nice to reason about, each table has rows and each row is one thing, I often try to explain this notion to people when they are building spreadsheets (the real data backbone of any organisation). Relationships (connections) are not presented as their own thing but merely another element inside a row, it is these relationships (the context), that gives data better meaning.
Documents
I wanted to give documents an honorary mention, as they are a common data structure and a more recent byproduct of the NOsql movement. Documents makes sense and nested information that does not need relationships (ie. no context needed outside of the document itself) becomes massively easy compared to tables. However, in most cases relationships to other documents become DIY and unless you are a database builder is something that you should probably not want to or have to manage.
Graphs

I have an obsession with graph databases, I feel like the world makes sense in graphs and think that graphs should really be called relational databases but that name has already been taken. Graphs have entities (aka nodes) that are much like a single row in a table or a single document. Graphs also have edges (aka vertices) that form the connection between the entities, but they are treated just as special as the entities themselves. The freedom to model any data structure is intoxicating, you can start with a whole bunch of disconnected nodes and then as your information builds you can join them to each other any which way. Some graph databases even let you store data on the edges themselves and let you query them efficiently which is super exciting. As you dig deeper into graph databases however you come up against decisions about should things be attributes (think person/email)or should they be joined nodes (think of email as its own node, joined via an edge to a person). This immense flexibility can feel a little too much and while graphs are beautiful, they can force decisions too early on the data model.
RDF (Resource Description Framework)

Beyond feeling a bit over engineered and lacking great commercial / open source solutions the approach seems like a natural progression from graphs. For those who have not read anything about RDFs (aka Triple stores) think of a SQL database made ONLY of one table, one massive table with just three fields (basic concept only).
- Subject: A reference to any other row in the table.
- Predicate: A string, usually a verb.
- Object: A value OR a reference to any other row in the table.
From this we can structure anything, it is awesome! At first it feels a bit verbose but it brings all data models down to their core elements, like the atom of data. The person row presented at the top would actually consist of multiple ‘triples’ where each one tells one part of the person story, eg. [1, person/name, ‘John’], [1, person/email, ‘[email protected]’]
A relationship (or edge) is just a triple that connects to entities and nested information are also just triples connected to a triple on the parent entity.
Pause & Reflect — when information changes
So for whatever reason we use one of the data structures above, it could be that tables (SQL) is proven, works and open source projects abound so we lock it in. We have been using the system now for six months and then we get to a point where we want to ask our database:
Dear database can you tell me when person 123’s email changed, what it was and what it was changed to, ideally who made that change also.
For all of the options above, we are mostly stuck with a non-response from our database, and Google will get some great responses that all would have helped six months ago but not today. We can can add timestamps, user add/update stamps and we can even split out emails to their own row/nodes but all of these only help us after some sort of implementation. Most likely we would then look at backups, logs or requests to find out this information if it is worth the hassle or trouble and as long as this is not a regular occurrence.
I personally feel that knowing the context of the when (the transaction) is just as critical as knowing the context of data through their relationships to other pieces of data. You may not need it on day one, but you will need it — as someone who loves Google Docs, being able to see all revisions to any document I have ever worked on is not required all the time but when it is needed it is amazing to have it there.
Datomic aka Facts
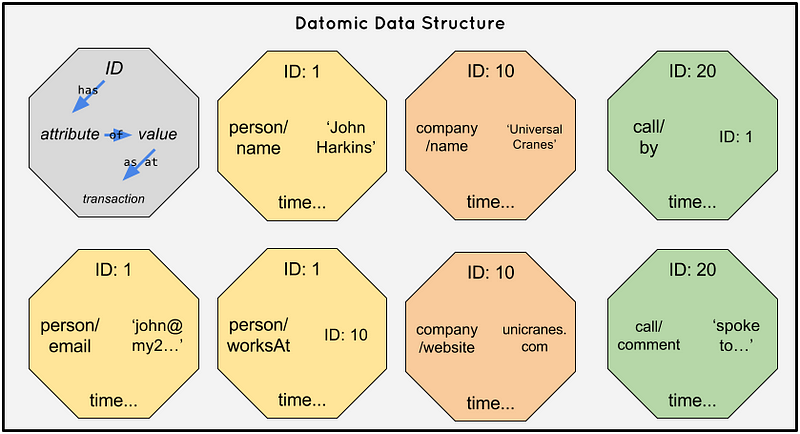
Datomic is very similar to RDF, but instead of triples we have items that consist of four basic elements:
- Entity (like Subject)
- Attribute (like predicate, but a nicer name IMO)
- Value (like Object, can be an actual value or a reference to another entity)
- Transaction (a special reference to another entity which itself contains facts about when, who, etc)
This simple and single approach to the view of your data removes the need to think so far in advance about everything you need. While changing schema might be non-trivial it does not affect the overall approach to the database structure. The future requests of the system do not have to be predicted to be prepared for and the icing on the cake is that this database is immutable, meaning that data put in is never removed, any changes are just new facts added into the system.
Conclusion
Next time you are considering some database architecture, take a bit of time to read about what else is out there. It might not mean you fork out the coin for a Datomic license but it may help you think twice before picking your previous default database system and schema.